As an umbrella term, DataOps can refer to a range of related technologies and processes, and is as much about cultural and organizational change as it is about the adoption of emerging data management products and services. For the purposes of this paper and its associated survey, DataOps is defined as follows:
DataOps is the alignment of people, process and technology to enable more agile and automated
approaches to data management. It aims to provide easier access to data to meet the demands of
various stakeholders who are part of the data supply chain (developers, data scientists, business
analysts, DevOps professionals, etc.) in support of a broad range of use cases.
DataOps is about reducing the complexity involved in data provisioning and enabling self-service access to data in order to accelerate the development of data-driven applications and data-driven decision-making, as well as supporting business agility in response to rapidly changing business requirements.
A key element of this is reducing ‘data friction,’ which arises when the demands of data consumers (such as data analysts, developers and senior decision-makers) are not met by data operators (e.g., data management and IT professionals). This is a perennial problem that has been exacerbated in recent years by the growing volume of data, as well as the increased number of data sources and use cases that results from escalated demand from application development and analytics projects. The term ‘DataOps’ itself has not yet become mainstream. However, the associated concepts and technologies are being widely adopted by enterprises as they seek to become more data-driven.
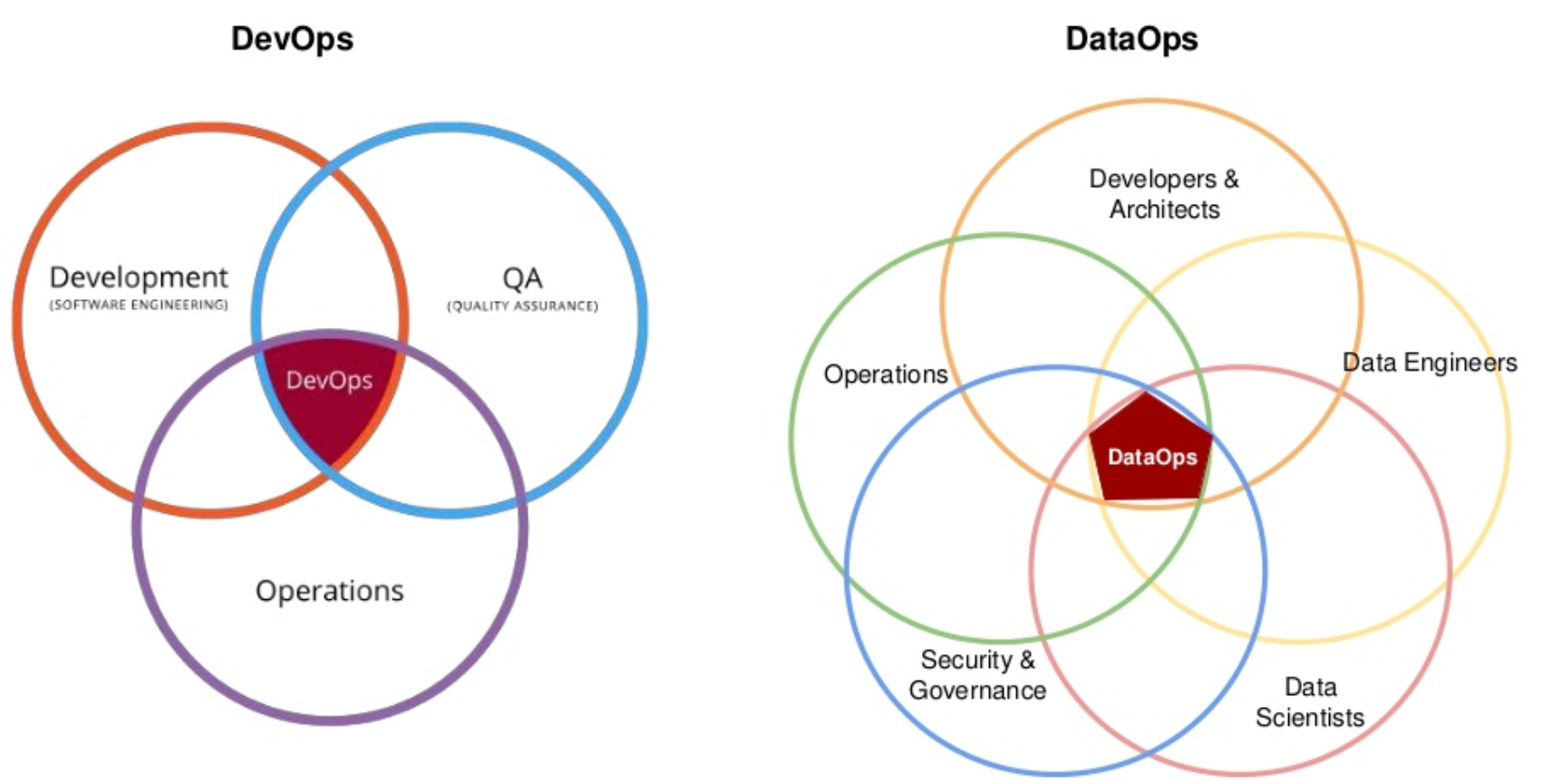
The value of DataOps has been most visible in DevOps environments where velocity is paramount and developers have a growing role in determining data access and usage requirements, as well as influencing the choice of more agile data management products and services. However, we see that DataOps is also penetrating other business processes, driven by the similar growing influence of data scientists and data engineers, for example. As such, DataOps is also related to the need for new cultural and organizational approaches to data management associated with the shift toward being more data-driven. This includes the formation of cross-functional collaborative teams that combine data scientists, data engineers and data analysts along with data management and IT professionals.
Here is our take on adoption of DataOps
Step 1 : Get familiar with The DataOps Manifesto – Through firsthand experience working with data across organizations, tools, and industries we have uncovered a better way to develop and deliver analytics that we call DataOps.
Step 2 : Everyone on the DataOps team needs at least one of the following tools to acquire, organize, prepare, and analyze/visualize data:
- Data access/ETL (e.g., Talend, StreamSets)
- Data catalog (e.g., Alation, Waterline)
- Enterprise data unification (e.g., Tamr)
- Data preparation (e.g., Alteryx, Trifacta)
- Data analysis and visualization (e.g., Tableau, Qlik)
Step 3 : Align to the DataOps goals:
- Continuous model deployment
- Promote repeatability
- Promote productivity – focus on core competencies
- Promote agility
- Promote self-service
Step 4: Match DevOps and DataOps with the processes and tools
Get Social