Big Data ecosystem is a never ending list of open source and proprietary solutions, and in my view, nearly all of them share common roots and fundamentals of good old platforms that we grew up with. With that as the basis, our topic for today is about architecture and design patterns in the Big Data world. Also, this will be my first blog in a series “Driven By Big Data” covering some more complex and exciting topics I see with various clients.
Let’s get started:
Most of us IT professionals, now or in the past have seen at least one big data problem and most of us have tried to solve for it. In my experience, there are plenty of reasons why those projects ended up as our happy hour conversations for years.
So how did we solve those problems?
It may have taken us a few heuristic techniques, prototypes, and ultimately solving for a repeatable pattern our scripts could handle. The same patterns lead to robust architecture frameworks; Lambda and Kappa being the two most prominent ones. Both strive to achieve a fault-tolerant, balanced latency, and optimum throughput system that conforms to the V’s of Big Data.

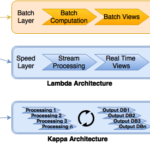
Lambda architecture consists of three layers: batch computation, speed (or real-time) processing, and a serving layer for responding to queries. It takes advantage of both batch and stream processors working alongside each other to mitigate any lost data sets or latency. However, the complexity arises when we try to maintain two different systems that are supposed to generate same results. This led to a more streamlined approach, Kappa. Here, every data stream feeds through a streaming layer with an ability to re-play a transaction into multiple serving data sets. I include a handy table with few recommended projects. I am sure there are more so feel free to reply and share.
That was easy, wasn’t it?
Let us look at a production scenario where we may have unpredictable data pattern and a few out-of-sequence event streams caused due to skew, server latency or failure. How do we check what architecture we should go with? Will it be Kappa for its simplicity or Lambda?
The answer is to look at the “life-of-a-event” carefully. This includes the size of each message, type of the event producer, capacity of a consumer system, and how the user will receive this information. One of the options we could take is to cache each transaction in the stream event store and replay the event in case of any discrepancies (Kappa) or store messages in a NoSQL data store by batch, perform an external lookup periodically in the stream to check for fallen messages (Lambda). A design choice like this can have a caveat, though, sacrificing latency for a “no-loss” system. My advice is to decide not just from what technology can do, but also on what the business requires. If I were a Financial institution, I would never want a missed transaction as opposed to a click stream that requires a lower latent solution.
Get Social